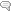Excel の xls ファイルは機械判読不可能?
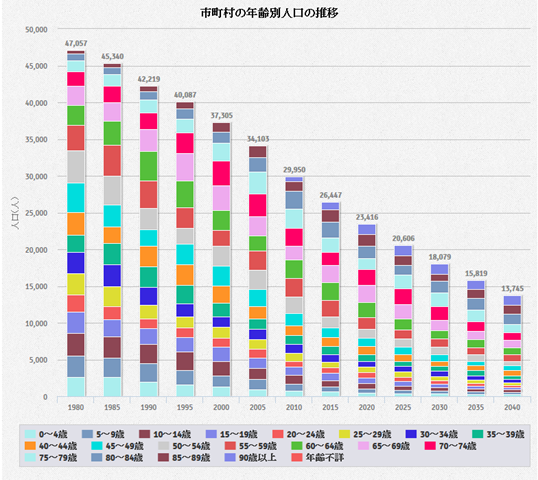
2014年5月8日前回のブログでも書いたように、最近、都道府県別・市町村別等の1980~2040年の5歳年齢階級別人口の推移のページを作成しました。その時に利用した日本のデータは、過去の分は国勢調査のデータを、将来の分は国立社会保障・人口問題研究所の将来推計を使用しています。
過去の国勢調査のデータを使用する場合に、特に市町村で問題になるのが市町村合併をどう処理するかです。人口の推移ではやはり市町村合併を考慮すべきだと思うので、過去の分では旧市町村の分を集計する必要があります。これに関しては、次世代統計利用システムの方で都道府県・市区町村コード情報がLOD(Linked Open Data)で提供されているので、それを利用することで市町村合併を機械で取得できるのでそれほど手間をかけずに処理をすることができました。また、国勢調査のデータは、今回は SDMX の API を使って取得しました。今後、Eurostat 等でも同じような処理でデータを取得できるというメリットがあると思っています。
一方、将来推計人口の方は、Excel ファイルでデータを公開しています。自分の場合は、Excel のファイルを C# で Excel Data Reader という OSS のライブラリーを使って処理しているので特に問題なく処理できました。むしろ、心配したのはデータの著作権の方でした。数字だけなので著作権の問題はないだろうと思って使いましたが、やはり気になるところです。
最近は、日本でもオープンデータの取り組みが始まり、統計データも API で公開されるようになって便利になりました。ただ、オープンデータの取り組みの中でどうも Excel の xls ファイルは機械判読ができない取り扱いになっているようなので気になって少し調べてみました。
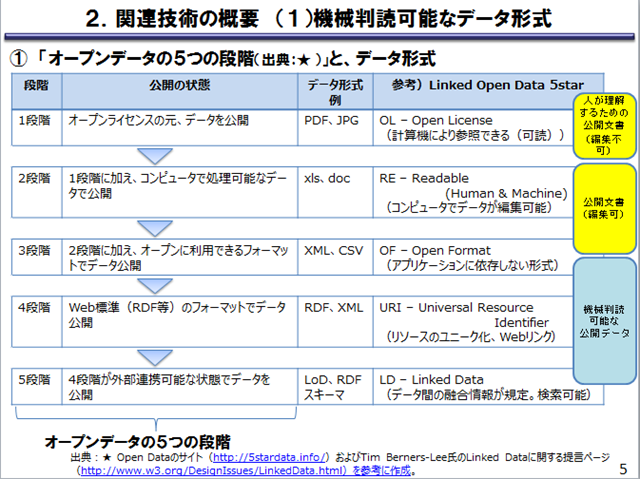
首相官邸の「電子行政オープンデータ実務者会議」のページの 「電子行政オープンデータに関連する決定」をみると「機械判読に適したデータ形式での公開の拡大」が結構大きな目標になっています。それで、「機械判読に適したデータ形式」とはどういう形式なのかを調べてみました。結論はよく分かりませんでしたが、第1回データWGの配布資料7の「データ形式・構造、データカタログに関する技術について」(小池データWG主査代理提出資料)という資料があり、機械判読可能なデータ形式の資料がありました。そこには「オープンデータの5つの段階」という話があって、Excel の xls ファイルは、「公開文書(編集可)」という位置づけで、「機械判読可能な公開データ」という位置づけにはなっていないようです。
自分の C# の Excel Data Reader を使った Excel ファイルの判読ルーティンのサンプルは以下のようなものです。
using System;
using System.Collections.Generic;
using System.Data;
using System.IO;
using System.Net.Http;
using Excel;
public void GetExcel(string url, string cachePath)
{
//毎回Excelのファイルをダウンロードするのは無駄なのでキャッシュしている
if (!File.Exists(cachePath))
{
//Webサイト(アドレス url)からのファイルの読み込み
using (var client = new HttpClient())
{
var sr = client.GetStreamAsync(url).Result;
var sw = File.Create(cachePath);
sr.CopyTo(sw);
sw.Close();
}
}
FileStream stream = File.OpenRead(cachePath);
IExcelDataReader excelReader = ExcelReaderFactory.CreateBinaryReader(stream);
//Excel Data Readerを使って、Excel のデータを DataSet クラスに読み込む。
DataSet result = excelReader.AsDataSet();
stream.Close();
int sheet = 2;
int column = 3;
int row = 8;
string s = result.Tables[sheet].Rows[row][column].ToString();
}
また、SMDX を使った国勢調査のデータの判読ルーティンのサンプルは以下のようなものです。
using System;
using System.Collections.Generic;
using System.Xml.Linq;
public void GetSmdx(string url)
{
//使用している名前空間を定義
XNamespace generic = "http://www.sdmx.org/resources/sdmxml/schemas/v2_1/data/generic";
//APIからXElementに読み込み
var xe = XElement.Load(url);
//LinqToXmlで各データの値を取得
var obsList = from q in xe.Descendants(generic + "Obs")
select q;
foreach (var obs in obsList)
{
string cat01 = "";
string cat02 = "";
string cat03 = "";
string area = "";
string time = "";
foreach (var obsKey in obs.Descendants(generic + "ObsKey").Descendants())
{
switch (obsKey.Attribute("id").Value)
{
case "cat01":
cat01 = obsKey.Attribute("value").Value;
break;
case "cat02":
cat02 = obsKey.Attribute("value").Value;
break;
case "cat03":
cat03 = obsKey.Attribute("value").Value;
break;
case "area":
area = obsKey.Attribute("value").Value;
break;
case "time":
time = obsKey.Attribute("value").Value;
break;
}
}
string value = obs.Descendants(generic + "ObsValue").First().Attribute("value").Value;
//以下で取得したデータを処理する
処理(cat01, cat02, cat03, area, time, value);
}
}
ほぼ SDMX と同じような処理で、公開された Excel データを自動処理することが可能です。違いといえば、SDMX の場合は定義された名前空間を使ってデータにアクセスできますが、xls ファイルの場合は、自分でシート番号とセルの位置を計算して指定してやる必要があるということです。確かに SDMX が名前空間が定義されているのでいつでもデータが取得できる確実性が高いのに対して、xls ファイルの場合は誰でもがすぐに表の形式を変更できるため次回も同じ方法でデータを取得できるという保証がないのが大きな欠点です。
しかし、データを作成する側から言えば、名前空間を定義してやらないといけないので、XML ファイルでデータを提供するのは結構大変だと思います。一方、xls ファイルでの公開は簡単だし、多くの人が簡単に利用できます。
Excel のファイルを扱うことができるフリーソフトとしては、Java では Apache POI、Ruby では Spreadsheet、PHP では PHPExcel、Python では Python Excel、JavaScript でも Sheet JS というソフトがあります。現在では、メジャーな言語であればExcel を扱うことのできる OSS のソフトが存在して、Excel を持っていなくても Excel のファイルを扱うことが可能になっています。

確かに数年前はExcel のファイルを Excel を使わずに扱うことは難しいことでした。でも、上の図は Seet JS のホームページですが、Excel がなくてもそのデータを使えるようにしようというエンジニアの努力によって、今では xls ファイルも商用のソフトを使用しなくても機械判読可能です。
資料を作った小池博氏は、「株式会社日立コンサルティング テクニカルディレクター」でデータ・ワーキンググループのワーキンググループ主査代理です。なぜ、xls ファイルを機械判読可能としなかったのでしょうか。確かに XML ファイルで提供される方がAPIとして利用する人にはベターなのですが、普通のユーザーには使い方が難くなるし、提供側でも作成に関してもそれなりに追加コストが必要です。そういう点を考えれば xls ファイルの機械判読がどの程度困難なのかで、XML 化する範囲やスピードについて結論は変わってくると思うのです。こういう資料を見ていると、LoD とか RDF というのは理想ですが、まだまだ一般の人が使えるような物ではありません。だから、Sheet JS のメンバーのような現実的な解決案を提供するという視点も重要です。そういう視点が欠けていることが日本のソフトウェアの高コスト体質を生んでいるように思います。