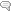Apple Swift の人気が凄い
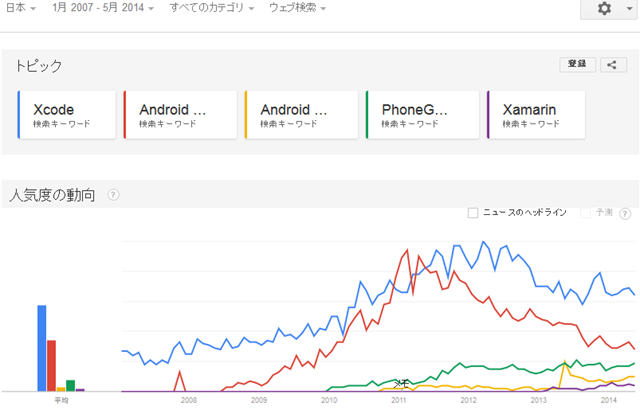
2014年6月9日6月1日に「Google トレンドでみるモバイルアプリ開発ツールの動向」という記事を書いたのですが、翌日のWWDC2014で新言語 Swift が発表されて話題になっています。Google トレンドでみても下の図のように凄い人気度です。
Swift の公開で iPhone アプリの作成もかなりやりやすくなるようなので、今後 Web アプリとネイティブアプリとの競争が一段と激しくなるように思っています。
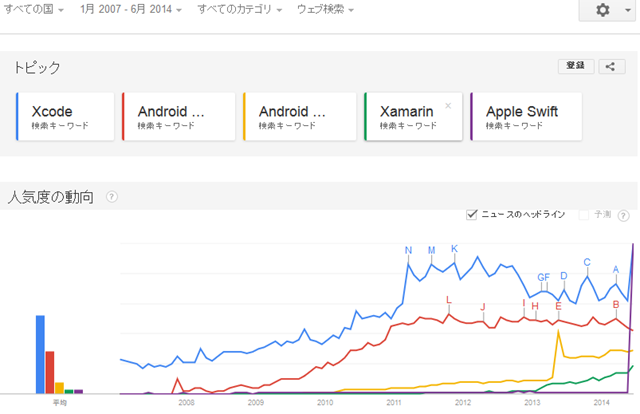
6月1日に「Google トレンドでみるモバイルアプリ開発ツールの動向」という記事を書いたのですが、翌日のWWDC2014で新言語 Swift が発表されて話題になっています。Google トレンドでみても下の図のように凄い人気度です。
Swift の公開で iPhone アプリの作成もかなりやりやすくなるようなので、今後 Web アプリとネイティブアプリとの競争が一段と激しくなるように思っています。
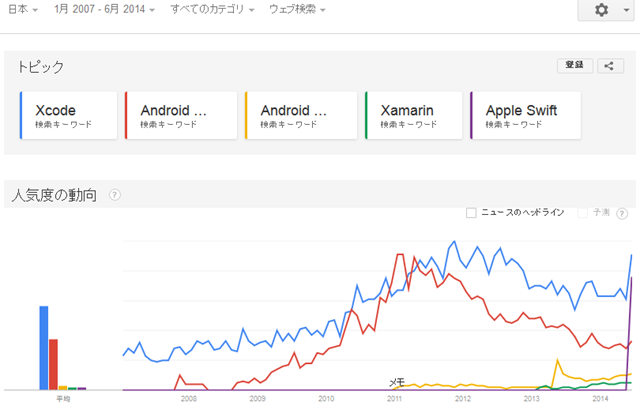
最近、モバイルアプリを作ろうと思って Xamarin を使い始めている。それで、Google トレンドで、モバイル開発ツールの動向をみてみた。
モバイル開発ツールで最も人気度の高いと思われるのは、世界的にみても日本でも、アップルの iOS 開発ツールである Xcodeである。
Android開発ツールの動向は、世界と日本ではかなり異なっている。世界的に見ると Android SDK は、2011年以降安定した人気度を持っているし、2013年5月に発表された Google の統合開発環境である Andoroid Studio もかなりの人気度を持っている。両者を併せると Xcode を上回る人気度になっており、Xcode がモバイルではない Mac の開発ツールでもあるということを考慮するとモバイル開発環境の人気度ナンバーワンといえるだろう。世界的に見ると Android 端末のシェアが拡大しているということも関係していると思われる。
一方で、日本の人気動向をみると、2010年から2011年にかけて、Android SDK の人気度が急上昇している。世の中がスマートフォンブームということで Android 端末が普及してきた時期であり、そのブームに乗ろうと思って Android 開発者が急増した時期である。その後、結局日本では iPhone の方が売れて Android の人気は上がらなかったので、Android SDK の人気度は急降下している。 このあたりも、横並び志向の強い日本の特徴がでている。製造業では、横並びでするというのは案外効率のいいことだと思うが、IT関係は二番が存在しづらい一人勝ちの世界なので、横並びをしていたのでは収益あがらないと思うのだがどうだろうか。
Xamarin は、世界的にはかなり人気度は上がっている。しかし、日本では、日本語のサポートが弱いということと、開発が受託中心でそれをチームで開発しているので、相当な力がかからない限り Xcode での開発を変更しようということにならないので、Xamarin の人気度があがる可能性はあまりないと思っている。
前回のブログでも書いたように、最近、都道府県別・市町村別等の1980~2040年の5歳年齢階級別人口の推移のページを作成しました。その時に利用した日本のデータは、過去の分は国勢調査のデータを、将来の分は国立社会保障・人口問題研究所の将来推計を使用しています。
過去の国勢調査のデータを使用する場合に、特に市町村で問題になるのが市町村合併をどう処理するかです。人口の推移ではやはり市町村合併を考慮すべきだと思うので、過去の分では旧市町村の分を集計する必要があります。これに関しては、次世代統計利用システムの方で都道府県・市区町村コード情報がLOD(Linked Open Data)で提供されているので、それを利用することで市町村合併を機械で取得できるのでそれほど手間をかけずに処理をすることができました。また、国勢調査のデータは、今回は SDMX の API を使って取得しました。今後、Eurostat 等でも同じような処理でデータを取得できるというメリットがあると思っています。
一方、将来推計人口の方は、Excel ファイルでデータを公開しています。自分の場合は、Excel のファイルを C# で Excel Data Reader という OSS のライブラリーを使って処理しているので特に問題なく処理できました。むしろ、心配したのはデータの著作権の方でした。数字だけなので著作権の問題はないだろうと思って使いましたが、やはり気になるところです。
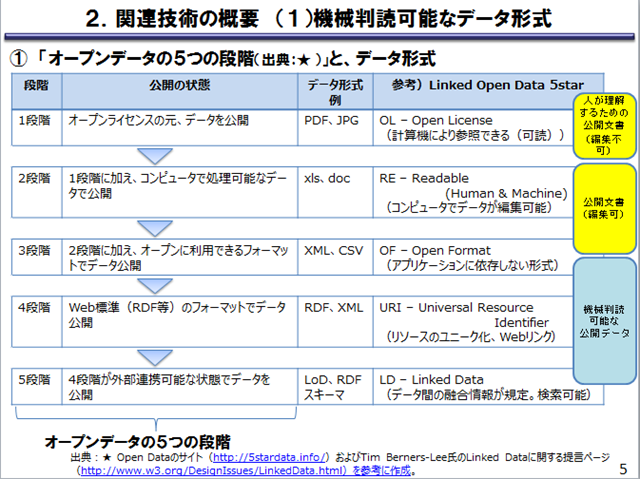
最近は、日本でもオープンデータの取り組みが始まり、統計データも API で公開されるようになって便利になりました。ただ、オープンデータの取り組みの中でどうも Excel の xls ファイルは機械判読ができない取り扱いになっているようなので気になって少し調べてみました。
首相官邸の「電子行政オープンデータ実務者会議」のページの 「電子行政オープンデータに関連する決定」をみると「機械判読に適したデータ形式での公開の拡大」が結構大きな目標になっています。それで、「機械判読に適したデータ形式」とはどういう形式なのかを調べてみました。結論はよく分かりませんでしたが、第1回データWGの配布資料7の「データ形式・構造、データカタログに関する技術について」(小池データWG主査代理提出資料)という資料があり、機械判読可能なデータ形式の資料がありました。そこには「オープンデータの5つの段階」という話があって、Excel の xls ファイルは、「公開文書(編集可)」という位置づけで、「機械判読可能な公開データ」という位置づけにはなっていないようです。
自分の C# の Excel Data Reader を使った Excel ファイルの判読ルーティンのサンプルは以下のようなものです。
using System;
using System.Collections.Generic;
using System.Data;
using System.IO;
using System.Net.Http;
using Excel;
public void GetExcel(string url, string cachePath)
{
//毎回Excelのファイルをダウンロードするのは無駄なのでキャッシュしている
if (!File.Exists(cachePath))
{
//Webサイト(アドレス url)からのファイルの読み込み
using (var client = new HttpClient())
{
var sr = client.GetStreamAsync(url).Result;
var sw = File.Create(cachePath);
sr.CopyTo(sw);
sw.Close();
}
}
FileStream stream = File.OpenRead(cachePath);
IExcelDataReader excelReader = ExcelReaderFactory.CreateBinaryReader(stream);
//Excel Data Readerを使って、Excel のデータを DataSet クラスに読み込む。
DataSet result = excelReader.AsDataSet();
stream.Close();
int sheet = 2;
int column = 3;
int row = 8;
string s = result.Tables[sheet].Rows[row][column].ToString();
}
また、SMDX を使った国勢調査のデータの判読ルーティンのサンプルは以下のようなものです。
using System;
using System.Collections.Generic;
using System.Xml.Linq;
public void GetSmdx(string url)
{
//使用している名前空間を定義
XNamespace generic = "http://www.sdmx.org/resources/sdmxml/schemas/v2_1/data/generic";
//APIからXElementに読み込み
var xe = XElement.Load(url);
//LinqToXmlで各データの値を取得
var obsList = from q in xe.Descendants(generic + "Obs")
select q;
foreach (var obs in obsList)
{
string cat01 = "";
string cat02 = "";
string cat03 = "";
string area = "";
string time = "";
foreach (var obsKey in obs.Descendants(generic + "ObsKey").Descendants())
{
switch (obsKey.Attribute("id").Value)
{
case "cat01":
cat01 = obsKey.Attribute("value").Value;
break;
case "cat02":
cat02 = obsKey.Attribute("value").Value;
break;
case "cat03":
cat03 = obsKey.Attribute("value").Value;
break;
case "area":
area = obsKey.Attribute("value").Value;
break;
case "time":
time = obsKey.Attribute("value").Value;
break;
}
}
string value = obs.Descendants(generic + "ObsValue").First().Attribute("value").Value;
//以下で取得したデータを処理する
処理(cat01, cat02, cat03, area, time, value);
}
}
ほぼ SDMX と同じような処理で、公開された Excel データを自動処理することが可能です。違いといえば、SDMX の場合は定義された名前空間を使ってデータにアクセスできますが、xls ファイルの場合は、自分でシート番号とセルの位置を計算して指定してやる必要があるということです。確かに SDMX が名前空間が定義されているのでいつでもデータが取得できる確実性が高いのに対して、xls ファイルの場合は誰でもがすぐに表の形式を変更できるため次回も同じ方法でデータを取得できるという保証がないのが大きな欠点です。
しかし、データを作成する側から言えば、名前空間を定義してやらないといけないので、XML ファイルでデータを提供するのは結構大変だと思います。一方、xls ファイルでの公開は簡単だし、多くの人が簡単に利用できます。
Excel のファイルを扱うことができるフリーソフトとしては、Java では Apache POI、Ruby では Spreadsheet、PHP では PHPExcel、Python では Python Excel、JavaScript でも Sheet JS というソフトがあります。現在では、メジャーな言語であればExcel を扱うことのできる OSS のソフトが存在して、Excel を持っていなくても Excel のファイルを扱うことが可能になっています。

確かに数年前はExcel のファイルを Excel を使わずに扱うことは難しいことでした。でも、上の図は Seet JS のホームページですが、Excel がなくてもそのデータを使えるようにしようというエンジニアの努力によって、今では xls ファイルも商用のソフトを使用しなくても機械判読可能です。
資料を作った小池博氏は、「株式会社日立コンサルティング テクニカルディレクター」でデータ・ワーキンググループのワーキンググループ主査代理です。なぜ、xls ファイルを機械判読可能としなかったのでしょうか。確かに XML ファイルで提供される方がAPIとして利用する人にはベターなのですが、普通のユーザーには使い方が難くなるし、提供側でも作成に関してもそれなりに追加コストが必要です。そういう点を考えれば xls ファイルの機械判読がどの程度困難なのかで、XML 化する範囲やスピードについて結論は変わってくると思うのです。こういう資料を見ていると、LoD とか RDF というのは理想ですが、まだまだ一般の人が使えるような物ではありません。だから、Sheet JS のメンバーのような現実的な解決案を提供するという視点も重要です。そういう視点が欠けていることが日本のソフトウェアの高コスト体質を生んでいるように思います。
5月1日のNHKのクローズアップ現代「極点社会~新たな人口減少クライシス~」で、高齢者が減少し“消滅”の危機にある代表として徳島県の三好市が取り上げられていた。そこで、三好市の1980年から2040年までの年齢階級別の人口の推移のグラフを作成してみた。
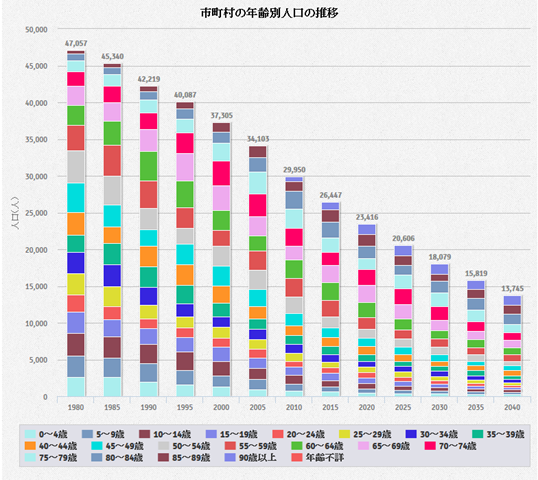
データについては、2010年までは国勢調査で、それ以降は国立社会保障・人口問題研究所の『日本の地域別将来推計人口(平成25年3月推計)』を使用しています。
このグラフを見ると三好市では、1980年には、池田町、三野町、山城町、井川町、東祖谷山村、西祖谷山村の6町村で47,057人の人口だっだのが、2010年には29,951人にまで減少し、2040年には13,745人にまで減少することが推計されています。非常に厳しい状況にあることが理解できると思います。もう少し詳しく数字をみると、もう一段と厳しい状態があることがわかります。以下が、0~34歳までの5歳階級別の人口の表です。
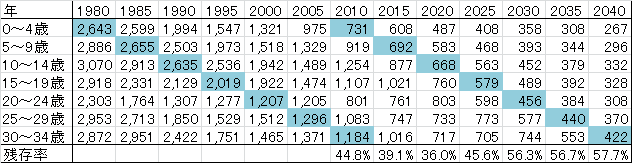
1980年に0~4歳だった人は2,643人ですが、30年後の2010年に30~34歳の人は1,184人です。正確ではないですが簡単にいえば、三好市で1976~1980年に生まれた人では、45%の人が地元に残り、それ以外の他の市町村に転出してしまっているということになります。1986~1990年に生まれた人だと地元に残る若者はわずかに36%です。1991~1995年に生まれた人は46%が地元に残ると推計されそれ以降も割合が増えていますが、それは純移動率の計算方法に原因があります。国立社会保障・人口問題研究所の地域別将来推計人口の「純移動率」の推計については以下のようになっています。
市区町村別・男女年齢別の純移動率は、一時的な要因によって大きく変化することがあるため、一定の規則性をみいだすことが難しい。そこで最終的に「日本の将来推計人口(平成 24 年 1 月推計)」(出生中位・死亡中位仮定)による推計値と一致させることを考慮し、全域的な傾向を一律に反映させることとした。「住民基本台帳人口移動報告」(総務省統計局)から平成 12(2000)年以降の動きをみると、転入超過数の地域差は平成 19(2007)年をピークとして縮小傾向にある。したがって、原則として、平成 17(2005)~22(2010)年に観察された市区町村別・男女年齢別純移動率を平成 27(2015)~32(2020)年にかけて定率で縮小させ、平成 27(2015)~32(2020)年以降の期間については縮小させた値を一定とする仮定を置いた。
確かに2008年のリーマンショックの影響によって東京圏への人口流入は減少し、地方でも人口の流出は抑えられています。しかし、2015年~2020年にかけてもこの傾向が続くかどうかは不明です。クローズアップ現代の「極点社会~新たな人口減少クライシス~」では、「地方の介護産業が高齢者を求め東京に進出し」、そこで働く若年女性も、「地方から東京へ移動し始めています」という問題を取り上げています。もし、今後地方からの若者の人口流出が増加するようなことになれば、地方の人口の減少は更に加速し、「極点社会」になってしまうのも近いと思います。
三好市は典型的な例ですが、県庁所在地の徳島市でも2010年の264,548人が2040年には206,368人と22%減少する推計になっています。東京圏への人口集中が進めばそれ以上に減少する可能性もあります。地方では県庁所在地でさえ大きく人口が減る時代になっています。地方は危機感を持って若者がどうしたら地域でいい生活を送れるのかを真剣に考えていかないといけないと思います。
年齢別人口のデータを取得するために SDMX を使ってみました。SDMX は、Statistics Data and Metadata eXchage の略で日本語でいえば統計データ及びメタデータ交換仕様といったところでしょうか。世界開発銀行、ヨーロッパ中央銀行、ヨーロッパ統計局、IMF、OECD、国連、世界銀行によって支援されています。
そういうことで、今後統計データを入手しようと思えば、SDMX を使うのがいいだろうと思って使い始めました。取りあえず今回はヨーロッパ統計局の人口関係のデータを取得して、下の図のようなグラフを描くところまでできました。各国の年齢階級別人口の推移のページで公開しています。
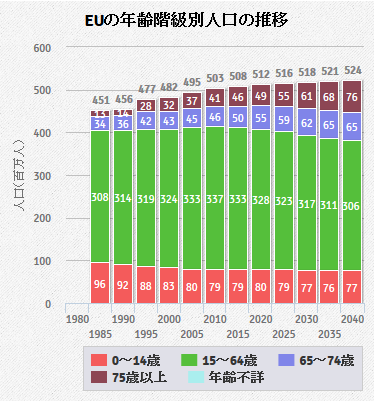
SDMXについては、初心者の段階なので、もう少し理解できるようになったら詳しい内容をブログに書きたいと思っています。
ヨーロッパは少子化が進んでいるというようなイメージがあったのですが、図をみればわかるようにヨーロッパ全体では人口は安定した動きになっています。少子化対策の優等生といわれるフランス(フランスの5歳年齢階級別人口の推移)やいち早く少子化が社会問題となったスウェーデン(スウェーデンの5歳年齢階級別人口の推移}では、リンクをクリックして見ていただければわかるのですが少子化対策が成功しているように思われます。
日本の全国及び各都道府県の年齢階級別人口の推移のページも作成しました。グラフをみると日本の少子化の深刻さがわかります。このままにしておけば百年もすれば日本の地方から人がいなくなるといってもいいような状態だと思います。日本も子供を育てやすい国になることを真剣に考えないといけないと思います。